01. ORMとは?
ORMとはオブジェクト関係マッピング(Object Relational Mapping)の略です。データベースのデータと各言語のオブジェクトの間でデータの変換と格納をおこなう技法です。ORM用に様々なライブラリがあります。これらのライブラリを使わない場合には、データベースから取得したデータを自分でオブジェクトに格納してゆく必要があるため手間と時間がかかります。またORM用のライブラリを用いるとデータベース間のプログラム移植性があがります。
もちろん欠点もあります。データベースにアクセスするためにSQLという言語を使いますが、ORMはこのSQLを自動的に組み立てます。この組み立てが実装者の意図したようになっておらず、データベースの性能を出し切れないSQLになってしまう可能性もあります。
しかしこの欠点についてもきちんとした対策があります。そのため特別な理由がないかぎりはORMライブラリを採用したほうが良いということになります。
特別な理由とは過去から動作しているシステムのリプレースですでに動作している実績のあるSQLがある場合や既存のデータベースの構造をORMに合わせて変更できないような場合です。このような場合にはORMを採用しないほうが良い場合があります。
それ以外の場合にはORMを用いるほうが良い結果になるでしょう。
↑目次
02. SQLAlchemyを用いる理由
PythonのORM用のライブラリは様々なものがあります。SQLAlchemy、dataset、Pony、PeeweeなどのORMライブラリがあります。その中でなぜSQLAlchemyを薦めるのか理由を説明します。
最大の理由は実績です。Pythonを用いて開発されているデータ可視化ツールではSQLAlchemyを利用している例が多くあります。dataset自体も内部でSQLAlchemyを用いています。
次に普及度です。Googleトレンドで上記のORMライブラリ+Pythonの名前で検索すると執筆時点ではSQLAlchemyが最も多く、次点でdatasetが続きます。すくなくとも現時点ではSQLAlchemyを使うのが良いと思います。(Pythonと一緒に検索している理由はdatasetは一般のIT用語なのdatasetで検索している人の大半はPythonのORMであるdatasetを検索していないと考えられるためです)もちろん業務で使っているORMが別の場合にはそちらを使えば良いとおもいます。またDjangoを使う場合にはDjango ORMを使うかもしれません。
最後にSQLに近い検索クエリの記述が可能ということです。ここでは複数のテーブルを結合するようなSQLを書きますが、SQLを知っている人が見たら、「ああ、なるほど!」と思う形の検索の記述にしています。
このようにSQLAlchemyをすすめるいくつもの理由があります。使ったことのない人は一度使ってみてください。
↑目次
03. データ構造の把握
前回まででPlotlyを用いたグラフ描画の基本はわかってきたと思います。今回は応用編ということで、データベースからデータを読み込んでプロットしてみます。前回と異なる部分は2つだけです。
- データベースからデータを読み込む
- 読み込んだデータをDataFrameに格納する
DataFrameに格納してしまえば、あとは前回同様、Plotlyで描画するだけです。
データを可視化しようと思う際にまず考えなければならないのはプロットの元となるデータの構造と格納先のDataFrameとの違いを把握することです。両者のデータ構造の違いがわかれば、データベースからどのようなデータ構造に成形してデータを読み込めばプログラムが簡潔になるか明確になるからです。
それではデータ構造を把握してゆきましょう。
データベース側のデータ構造
今回用いるDBは以前とりあげたランキングチェックツールです。2021-05-08時点でのER図とテーブル定義は以下のようになっています。
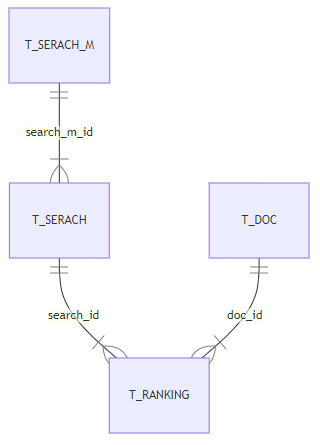
それぞれのテーブル定義と対応するSQLAlchemyのクラスは以下のようになっています。
T_SERCH_M(検索マスタ)
| 項目名 |
型 |
KEY |
説明 |
| id |
int |
PK |
検索マスタID |
| keywords |
text |
|
キーワード文字列のタブ区切り |
class TSearchM(Base):
__tablename__ = 't_search_m'
id = Column(Integer, primary_key=True, autoincrement=True)
keywords = Column(String(256), nullable=False)
T_SEARCH(検索)
| 項目名 |
型 |
KEY |
説明 |
| id |
int |
PK |
検索ID |
| search_m_id |
int |
FK |
検索マスタID |
| search_datetime |
int |
|
検索日時 |
class TSearch(Base):
__tablename__ = 't_search'
id = Column(Integer, primary_key=True, autoincrement=True)
search_m_id = Column(Integer, nullable=False)
search_datetime = Column(DateTime, nullable=False)
T_RANKING(ランキング)
| 項目名 |
型 |
KEY |
説明 |
| id |
int |
PK |
ランキングID |
| search_id |
int |
FK |
外部キー(検索ID) |
| doc_id |
int |
FK |
外部キー(ドキュメントID) |
| ranking |
int |
|
検索順位 |
class TRanking(Base):
__tablename__ = 't_ranking'
__table_args__ = (UniqueConstraint('search_id','ranking'),{})
id = Column(Integer, primary_key=True, autoincrement=True)
search_id = Column(Integer, nullable=False)
doc_id = Column(Integer, nullable=False)
ranking = Column(Integer, nullable=False)
T_DOC(ドキュメント)
| 項目名 |
型 |
KEY |
説明 |
| id |
int |
PK |
ドキュメントID |
| link_url |
text |
|
リンクURL |
| title |
text |
|
タイトル |
| mypage_flg |
int |
|
自ページフラグ |
class TDoc(Base):
__tablename__ = 't_doc'
id = Column(Integer, primary_key=True, autoincrement=True)
link_url = Column(String(2083), nullable=False)
title = Column(String(128))
mypage_flg = Column(Integer, nullable=False)
この表の中からグラフで描画するデータを探します。
- 検索キーワードごとにグラフを作成
- 横軸は検索日付
- 縦軸は順位
- サイト(ドキュメント)ごとに色を分けて日付経過による順位変動を折れ線で表示
以上を考えて、テーブル(表)から抽出するデータを考えます。すると上記の表の黄色のマーカーの部分が抽出するデータということがわかります。それぞれプロットの対象となるデータと黄色で色づけた項目の対応は以下となります。
グラフのデータと表の項目の対応
| 表の項目 |
データベースの表 |
データベースの項目 |
| 検索キーワード |
T_SERARCH_M |
keywords |
| サイトタイトル |
T_DOC |
title |
| 検索日付 |
T_SERARCH |
search_datetime |
| 順位 |
T_RANKING |
ranking |
表間の結合
| 左表.項目 |
右表.項目 |
| TSearchM.id |
TSearch.search_m_id |
| TSearch.id |
TRanking.search_id |
| TRanking.doc_id |
TDoc.id |
このグラフデータの表と項目の対応をみて4つのテーブルが必要ということ(T_SEARCH_M, T_SEARCH, T_DOC, T_RANKIG)がわかります。またER図から表間の結合がわかります。データ構造がわかったためSQLAlchemyを用いたSQL発行部分は以下のようになります。黄色の緑のマーカーはそれぞれの表の部分と同じ箇所になります。こうしてみるとSQLAlchemyが非常にわかりやすいのが理解できるとおもいます。
result = session.query(
TSearchM.keywords
,TDoc.title
,TSearch.search_datetime
,TRanking.ranking
).join(
TSearch,TSearchM.id == TSearch.search_m_id
).join(
TRanking,TSearch.id == TRanking.search_id
).join(
TDoc,TRanking.doc_id == TDoc.id
).order_by(
TSearchM.keywords
,TDoc.title
,TSearch.search_datetime
,TRanking.ranking
).all()
最後のorder_byではソートをおこなっています。
↑目次
04. データを取得する
実際にresultからデータを取得する部分は以下のようになります。
for raw in result:
print(str(raw.search_datetime) + "\t" + raw.title + "\t" + str(raw.ranking))
単純にresultをforで回して取得します。
↑目次
05. DataFrameにデータを格納する
resultからデータを取得する方法がわかったところで、DataFrameにデータを格納します。
それぞれの軸に対応するデータを別々の配列として格納するので以下のようになります。日付と順位の配列の中には様々なサイトのデータが混在することになりますが、サイトの配列で日付と順位がどのサイトのデータかわかるようになっています。特に難しいことはなくfor ループの中でそれぞれの配列でデータを追加してゆきます。
date_axis=[]
title_axis=[]
ranking_axis=[]
for raw in result:
print(str(raw.search_datetime) + "\t" + raw.title + "\t" + str(raw.ranking))
date_axis.append(raw.search_datetime)
title_axis.append(raw.title)
ranking_axis.append(raw.ranking)
df = pd.DataFrame({
"サイト" : title_axis,
"日付" : date_axis,
"順位" : ranking_axis
})
配列にデータを格納したらプロットの部分をみてゆきます。
fig = px.line(df, x="日付", y="順位", color='サイト')
fig.update_yaxes(autorange='reversed')
fig.update_xaxes(tickformat="%Y-%m-%d")
fig.update_layout(title=keywords)
fig.show()
1行目でデータフレームを指定しグラフのx軸、y軸、線の区分けにどのデータを用いるかを指定しています。
2行目でy軸の上下を反転しています。
3行目はx軸の日付のフォーマットを指定しています。
4行目はグラフの一番上に表示するタイトルを変更しています。
最後の行でグラフを表示しています。
↑目次
06. 全体のソースコード
importやデータベースへの接続も含めて今までの結果をまとめた全体のソースコードは以下のようになります。検索マスタにあるレコードの数だけ、ウィンドウが開いてグラフが描画されるため、それだと困る場合には最後のfor文の部分を変更してください。
# -*- coding: utf-8 -*-
import sqlalchemy
from sqlalchemy import Column, Integer, String, Date, Float, DateTime
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.sql.schema import UniqueConstraint
import pandas as pd
import plotly.express as px
Base = declarative_base()
class TSearchM(Base):
__tablename__ = 't_search_m'
id = Column(Integer, primary_key=True, autoincrement=True)
keywords = Column(String(256), nullable=False)
class TSearch(Base):
__tablename__ = 't_search'
id = Column(Integer, primary_key=True, autoincrement=True)
search_m_id = Column(Integer, nullable=False)
search_datetime = Column(DateTime, nullable=False)
class TRanking(Base):
__tablename__ = 't_ranking'
__table_args__ = (UniqueConstraint('search_id','ranking'),{})
id = Column(Integer, primary_key=True, autoincrement=True)
search_id = Column(Integer, nullable=False)
doc_id = Column(Integer, nullable=False)
ranking = Column(Integer, nullable=False)
class TDoc(Base):
__tablename__ = 't_doc'
id = Column(Integer, primary_key=True, autoincrement=True)
link_url = Column(String(2083), nullable=False)
title = Column(String(128))
mypage_flg = Column(Integer, nullable=False)
def selectRanking():
"""
DBからランキング情報を取得しキーワードとデータフレームのタプルの配列にして返す
"""
connect_string = "sqlite:///ranking.sqlite3"
engine = sqlalchemy.create_engine(connect_string, echo=False) # SQLとデータを出力したい場合はecho=Trueにする
try:
session = scoped_session(
sessionmaker(
autocommit = False,
autoflush = True,
bind = engine))
Base.query = session.query_property()
keywords_rows = session.query(TSearchM).all()
ret = []
for kw_row in keywords_rows:
result = session.query(
TSearchM.keywords
,TDoc.title
,TSearch.search_datetime
,TRanking.ranking
).join(
TSearch,TSearchM.id == TSearch.search_m_id
).join(
TRanking,TSearch.id == TRanking.search_id
).join(
TDoc,TRanking.doc_id == TDoc.id
).filter(
TSearchM.id == kw_row.id
).order_by(
TSearchM.keywords
,TDoc.title
,TSearch.search_datetime
,TRanking.ranking
).all()
date_axis=[]
title_axis=[]
ranking_axis=[]
for raw in result:
print(str(raw.search_datetime) + "\t" + raw.title + "\t" + str(raw.ranking))
date_axis.append(raw.search_datetime)
title_axis.append(raw.title)
ranking_axis.append(raw.ranking)
df = pd.DataFrame({
"サイト" : title_axis,
"日付" : date_axis,
"順位" : ranking_axis
})
ret.append( (kw_row.keywords,df))
except Exception:
raise
else:
session.close()
finally:
engine.dispose()
return ret
kw_df_list=selectRanking()
for keywords, df in kw_df_list:
fig = px.line(df, x="日付", y="順位", color='サイト')
fig.update_yaxes(autorange='reversed')
fig.update_xaxes(tickformat="%Y-%m-%d")
fig.update_layout(title=keywords)
fig.show()
上記ファイルをRankingPlot.pyという名前で保存したとすると実行は以下のようにおこないます。
py RankingPlot.py
以下のようなグラフが表示されました。
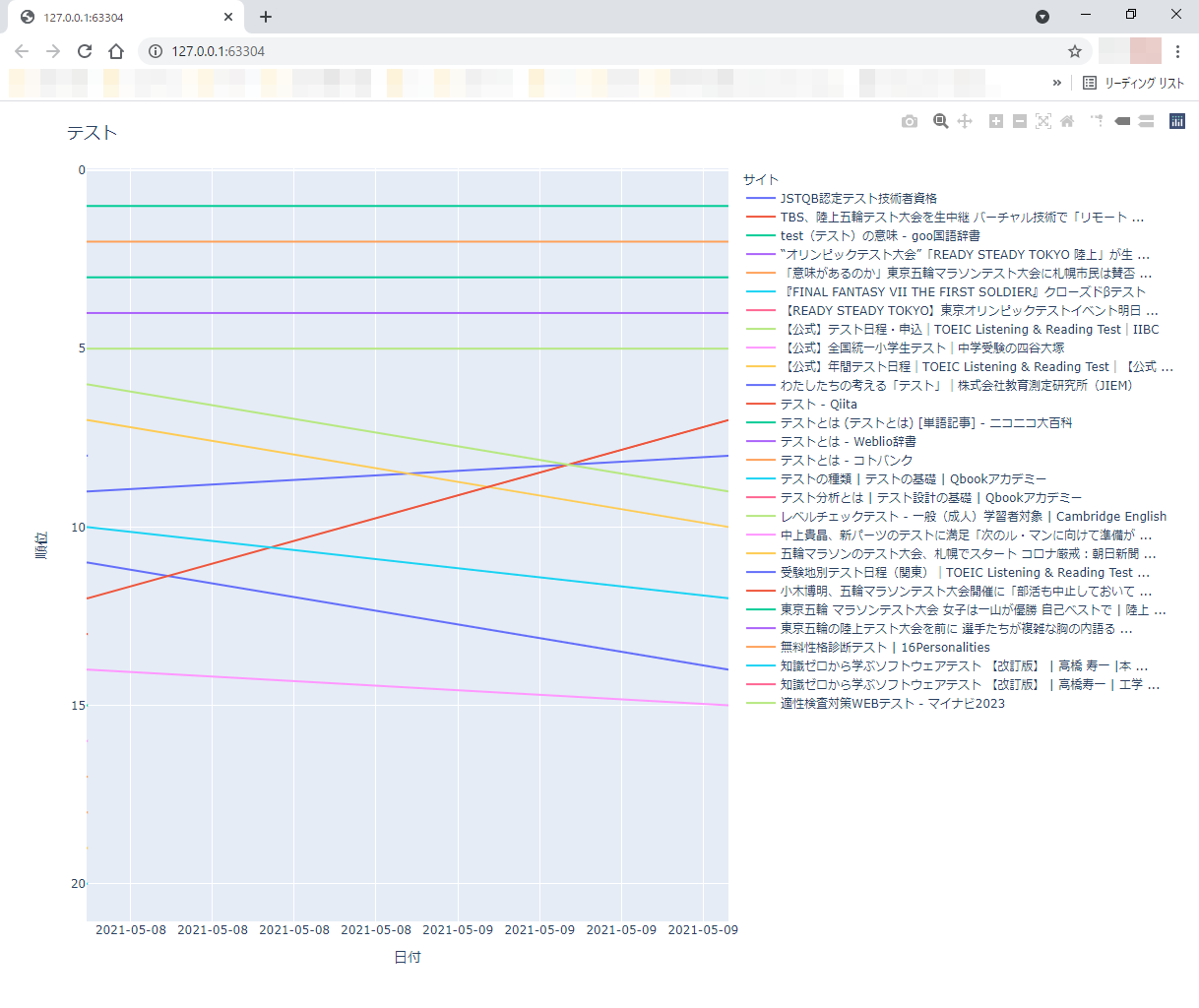
↑目次
07. 課題
グラフをみて気になる部分を修正してゆきます。今回の場合、以下が気になりました。
- サイトの凡例が直近のランキング順になっていない
- 折れ線だと1日しか登場していないサイトの線が引かれないのでわからない
最初の課題についてはソート順をキーワード、日付の降順、ランキングの昇順、サイトの順にすればゆけるはずです。
次の課題については、線を引くだけでなくドットを入れることで対応できないかPlotlyのオプションを調べてみます。
ソート順の変更
ソート順を変更してゆきます。
変更前
).order_by(
TSearchM.keywords
,TDoc.title
,TSearch.search_datetime
,TRanking.ranking
).all()
変更後
).order_by(
TSearchM.keywords
,TSearch.search_datetime.desc()
,TRanking.ranking
,TDoc.title
).all()
ソートの優先項目を入れ換えると同時に、日付に関しては降順に設定しています。降順にするには.desc()とします。これで直近のグラフからプロットされることになりますが、線グラフは過去から線を引いても直近から線を引いても結果は変わらないはずです。これによに直近のランキング順にサイトのタイトルがPlotlyに渡されるはずなので凡例が直近のランキング順に変わるはずです。試しに表示してみると以下のように直近のランキング順に変わりました。
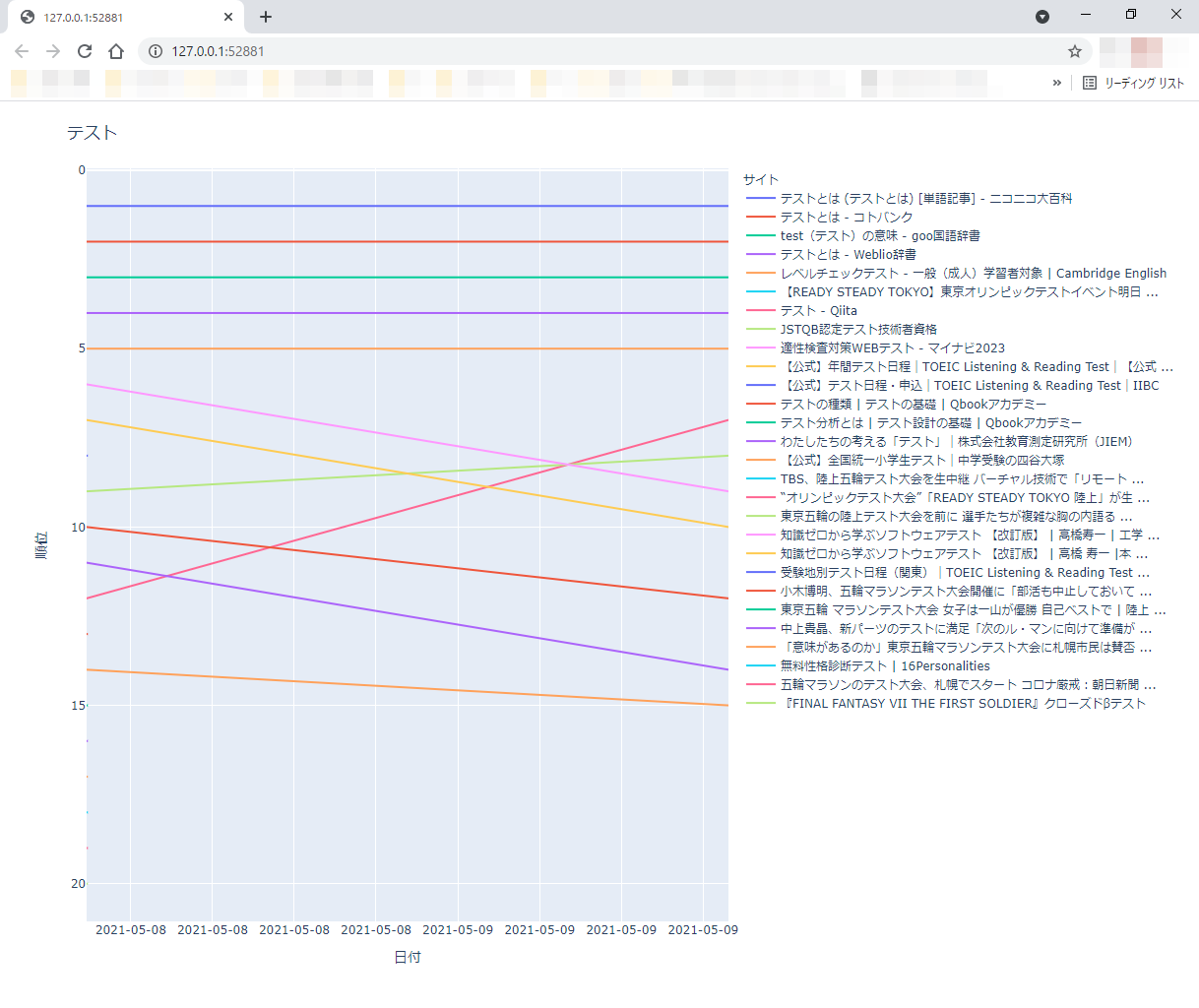
折れ線のプロット点をマークする方法は?
折れ線だけでなくプロット点をマークしてゆきます。ところがここで問題が生じました。Plotlyのサイトの折れ線グラフの説明をみてみたところPlotly Expressを用いてLineとマークを同時に出すことはできません。Lineとマークを同時に出力するにはGraph Objectを用いてデータを作成します。無理やりPlotly Expressで作成したFigureのデータを書き換えることで対応することも考えましたが、素直にGraph Objectを用いてプログラムを書き換えることにしました(Graph Objectを用いると順位外の際に折れ線を切ることもできるのでこちらのほうが目的に合致しています)。
データ構造から変わるため次回の記事に持ち越すこととしました。
↑目次
08. まとめ
今回は実際にSQLAlchemyを用いてデータベースからデータを読み込みPlotlyを用いてグラフをプロットしてみました。
次回はGraph Objectを用いてPlotly Expressでは実現できなかった課題を解決します。
↑目次



この記事へのコメント
コメントはまだありません。
コメントを送る