Plotly Expressを用いてヒストグラムを描画します。 Plotly ExpressはPlotlyで用いられる高レベルインターフェースです。 細かいレイアウトなどをライブラリに任せることができ、簡単にグラフを描画することができます。 公式サイトHistograms in Pythonと異なりここではGraph Objectsについては扱っていません。一方データの取り扱いやPlotly Expressのオプションについては、公式ページに記載されていない内容も解説し入門者が理解しやすくしてみました。

データの準備
まずは描画対象となるデータをみてみます。
import plotly.express as px
df = px.data.tips()
print(df)
実行結果は以下のようになりました。
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
金額とチップ、性別、喫煙の有無、曜日、時間帯、サイズなどが表示さています。レストランや飲食店のデータでしょうか。 そのまま手はわかりにくいので、dfのカラムをすべて日本語に直します。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
print(df)
実行結果は以下のようになります。
支払合計額 チップ 性別 喫煙者 曜日 時間帯 サイズ
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
ヒストグラムを描く
ヒストグラムは分析対象の分布密度を見たい時に用いるグラフです。 分布を見るときには分布図を使うときもあります。分布図では正の相関や負の相関が疑われる場合に、トレンドラインを描画して相関関係を調べるのに用います。一方ヒストグラムでは棒グラフを用い密度分布を調べます。 例えば顧客の支払合計額をいくつかの範囲に区切り、どの合計帯がメインの顧客かを分析したりします。 場合によって顧客ではなく商品の価格帯で分析することもあります。 どの価格帯がメインの商品になっているかを知ることで商品の仕入れに役立てたり効果的な公告を打つことができます。
ここでは先程見たデータを元に、支払合計額の価格帯ごとの来店者数をグラフ表示してみます。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額')
fig.show()
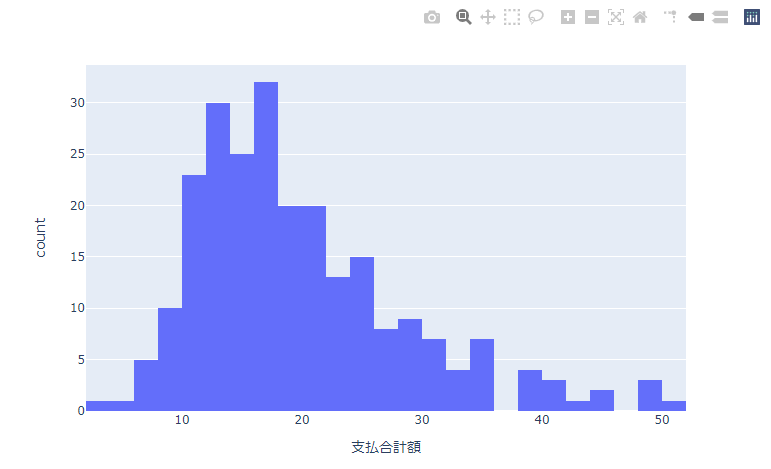
この結果をみてみると支払合計額が$12~18の顧客がメインであることがわかります。
正規化(標準化)
正規化(標準化)とは全体のパーセントが100%になるように、 何らかの値(確率や面積、長さなど)が1になるように全体を調整する方法です。 全体を100%もしくは1に揃えることでシュミレーションをおこなう際に、 擬似的なデータを生成したり予測値を立てることが簡単になったり、 データの特徴を重ね合わせて比較することができます。
正規化(標準化)をおこなうにはhistnormのパラメータで正規化(標準化)の方法を指定します。
| histnormで指定するパラメータ | 説明 |
|---|---|
| percent | 全体が100%になるように正規化する |
| probability | 確率が1になるように正規化する |
| density | 密度で正規化する |
| probability density | 確率+密度で正規化する |
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額',histnorm='percent')
fig.show()
パーセント(percent)
それれの価格帯が全体の何%かをあらわします。
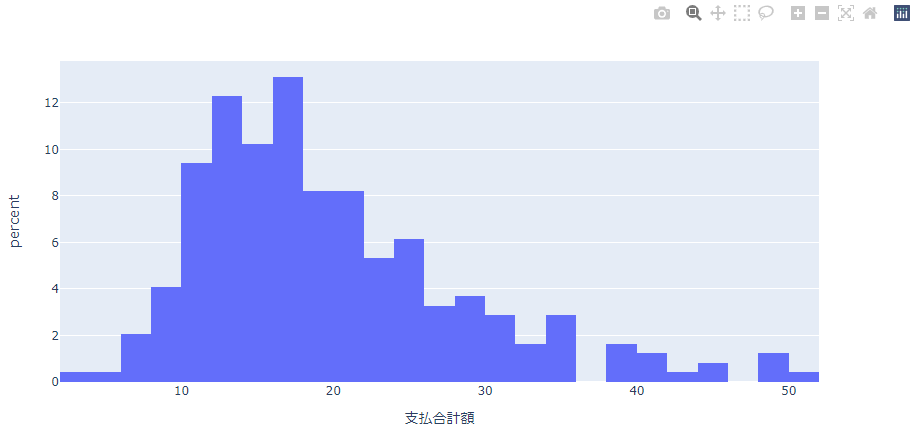
グラフをみてもらえばわかる通りそれほど難しくは無いとおもいます。
確率(probability)
100=1.0として確率であらわします。
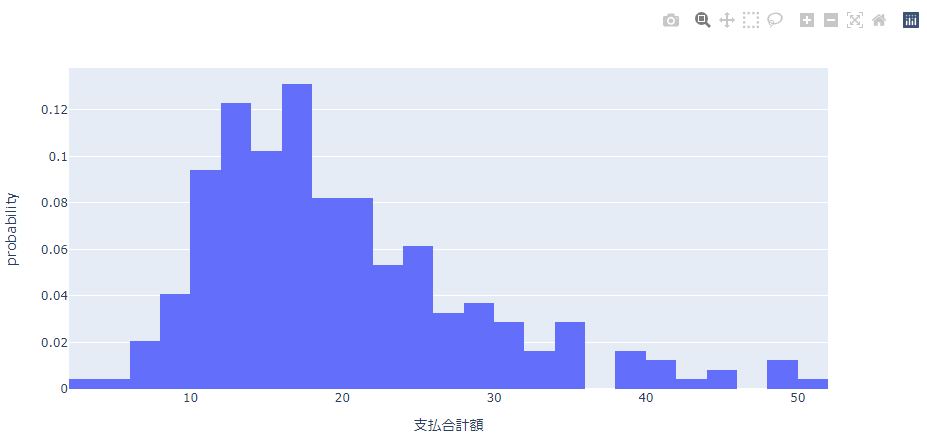
これもパーセント(百分率)が確率になっただけでそれほど難しくないとおもいます。
密度(density)
密度はx軸が1の間にどれだけデータ数があるかをあらわします。
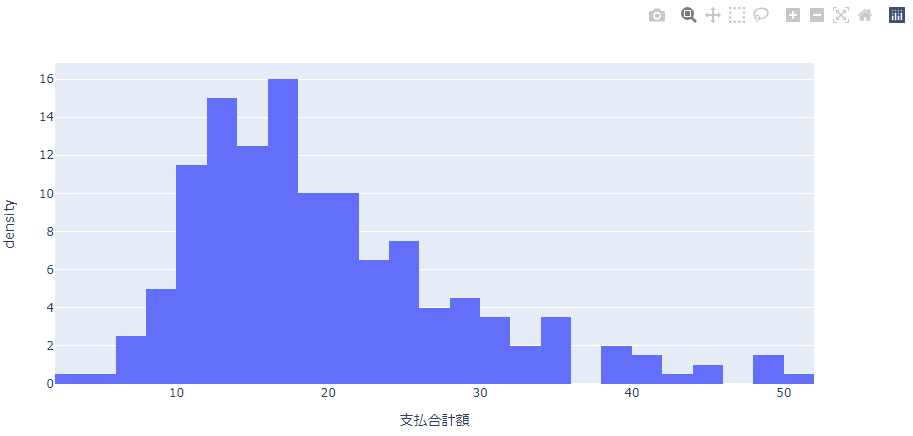
例えばこのヒストグラムではx軸は2の幅になっています。そのため密度が16ということはデータ数は16×2=32のデータがあることがわかります。
確率×密度(probability density)
確率密度分布と呼ばれるものです。量子力学を勉強した人ことのある理学系の人であれば知っているかせしれません。面積が確率と等しくなるように正規化されます。
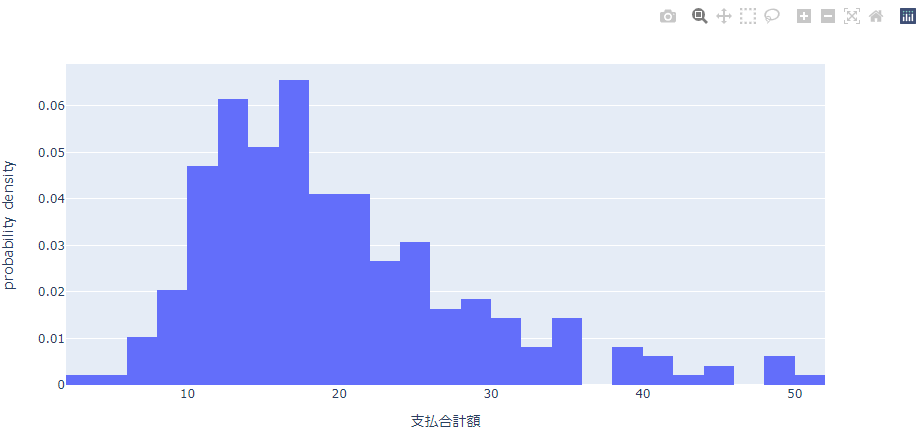
グラフ全体の面積は1となります。例えば支払合計額が$10以上$20未満の顧客である確率は$10≦支払合計額<$20の区間のグラフの面積に等しくなります。
合計・平均・最小・最大値の表示
histfuncで縦軸に表示する値をデータ数・合計・平均・最小値・最大値で指定できます。
| histfuncで指定するパラメータ | 説明 |
|---|---|
| count | データ数 |
| sum | 合計 |
| avg | 平均 |
| min | 最小値 |
| max | 最大値 |
デフォルトではデータ数(count)になっています。count以外では引数としてyを指定する必要があります。
合計(sum)
各金額帯での支払合計の合計(売上)をみてみます。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額',y='支払合計額',histfunc='sum')
fig.show()
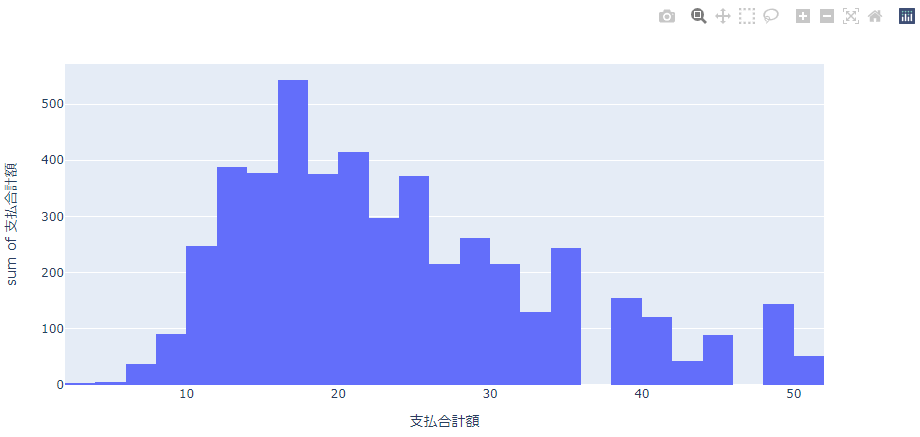
平均(avg)
価格帯ごとのチップの支払額平均を表示してみます。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額', y='チップ', histfunc='avg')
fig.show()
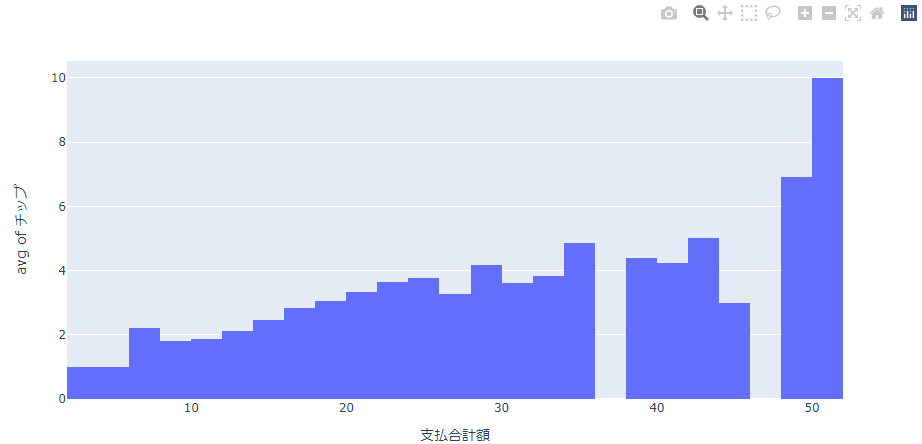
最小値(min)
価格帯ごとのチップの最小額を表示してみます。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額', y='チップ', histfunc='min')
fig.show()
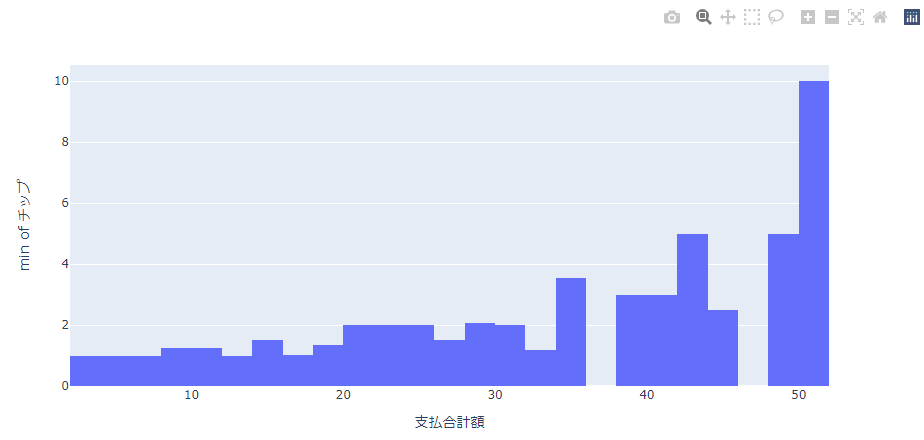
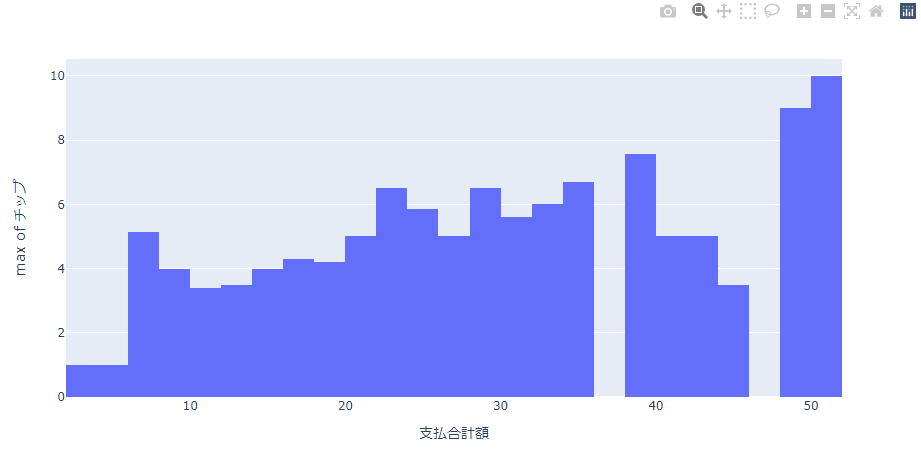
最大値(max)
価格帯ごとのチップの最大値を表示してみます。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額', y='チップ', histfunc='max')
fig.show()
解像度の調整(bins)
先のグラフでは分解能が小さく誤差のせいか値が上下にぶれています。 頂点が2箇所にあったり、高額帯で島になっている領域もあります。 サンプル数に対して、分解能が高すぎる可能性があるため、ヒストグラムの棒(bin)の数を減らして分解能を下ます。
棒の数はnbinsで指定しますが、だいたいの数を入れるとplotlyexpressできりのよい区切りで調整して表示してくれます。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額', nbins=20)
fig.show()
実行結果
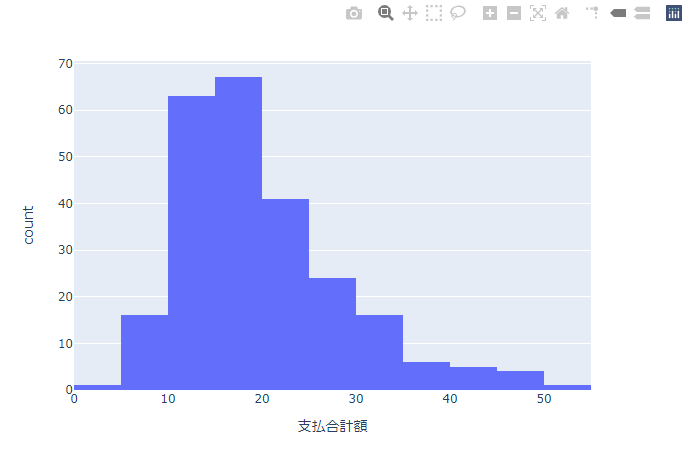
このくらいの分解能であれば、グラフが上下せず全体の傾向が把握できていることがわかります。
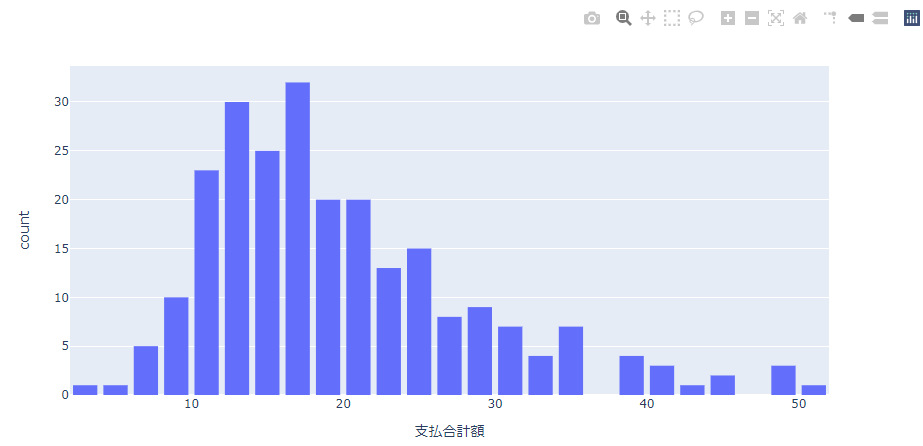
棒の間を離す
連続データを区切ってを分析する場合、棒グラフはくっついた状態で表示されます。離して表示する場合には以下のようにupdate_layoutでbargapを指定します。
fig = px.histogram(df, x='支払合計額')
fig.update_layout(bargap=0.2)
fig.show()
実行結果
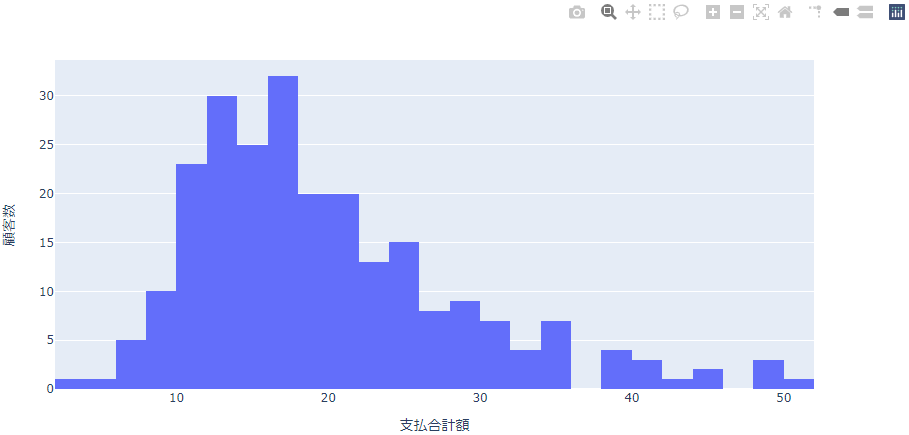
縦軸の名前を変える
ヒストグラムでは縦軸はデフォルトで「count」と表示されますが、これを「顧客数」と変更します。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額')
fig.update_layout(yaxis=dict(title='顧客数'))
fig.show()
色分け
複数のグループを色分けしてヒストグラムを描画することができます。
例えば男性と女性に分けて色分けしたヒストグラムを描く場合にはcolorオプションで項目名を指定します。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額', color='性別')
fig.update_layout(yaxis=dict(title='顧客数'))
fig.show()
実行結果
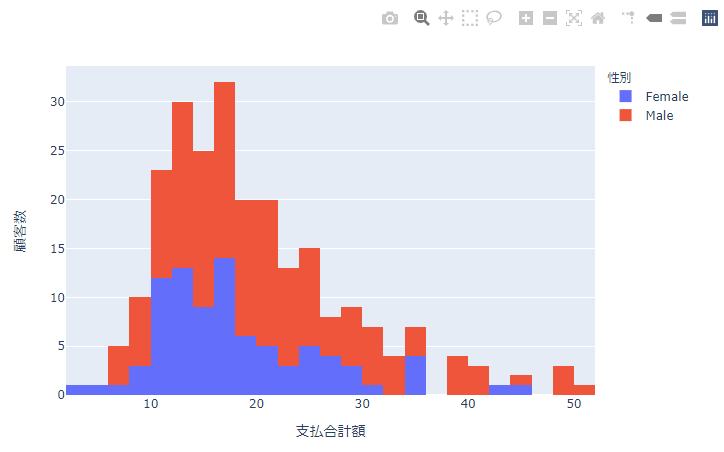
パターン分け
グループを色分けするでなく別軸でパターン分けすることもできます。
パターン分けするにはpattern_shapeオプションを使います。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額', color='性別', pattern_shape='喫煙者')
fig.update_layout(yaxis=dict(title='顧客数'))
fig.show()
実行結果
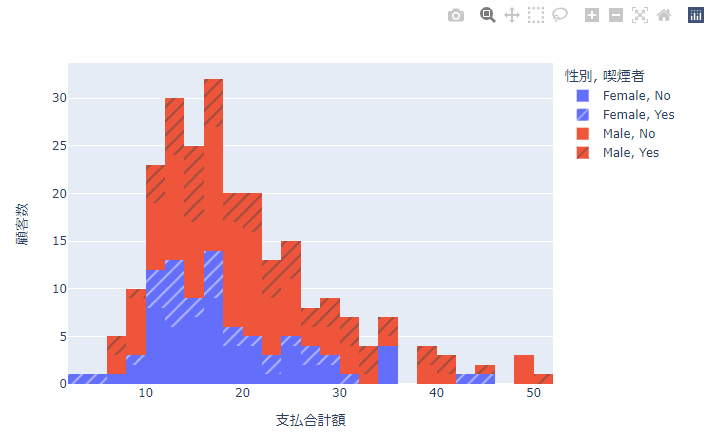
以下のようなエラーが出る場合はplotlyのバージョンが古いためupgradeする必要があります。
TypeError: histogram() got an unexpected keyword argument 'pattern_shape'
pip install plotly --upgrade
分布の可視化 marginal
rug表示
marginalを指定することで一つ一つのデータのx軸分布を可視化するように表示することができます。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='支払合計額', color='性別', marginal="rug", hover_data=df.columns)
fig.update_layout(yaxis=dict(title='顧客数'))
fig.show()
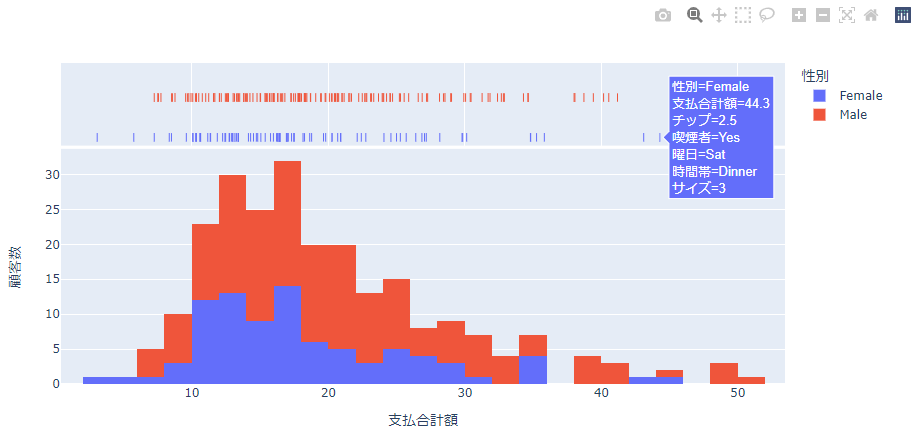
箱ひげ図 box
marginal="box"を指定すると分布を箱ひげ図で表示します。
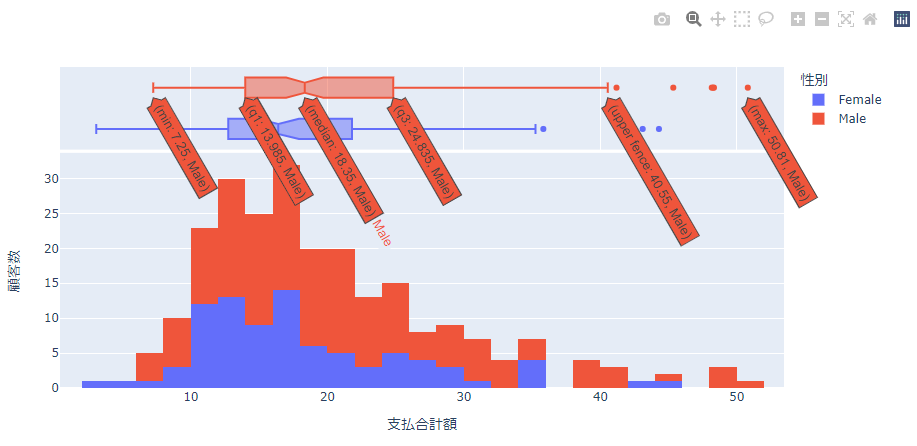
バイオリン図 violin
marginal="violin"を指定すると分布をバイオリン図で表示します。
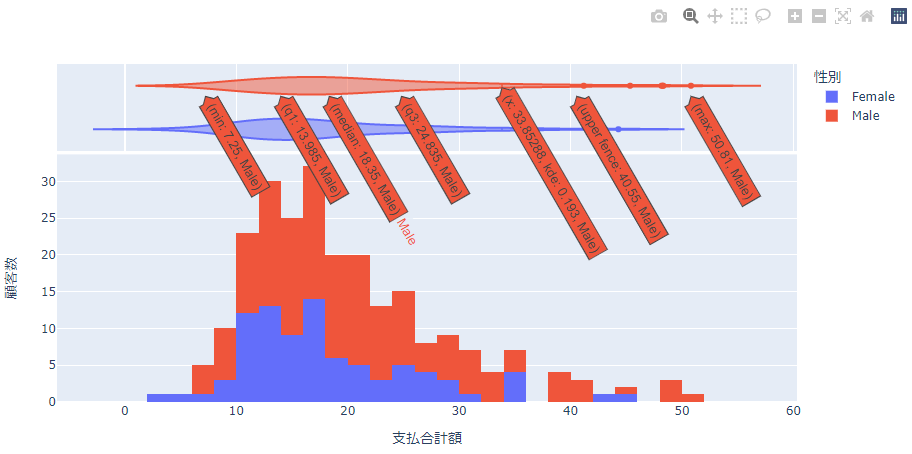
グループでヒストグラムを描く
いままでは連続値を範囲に区切ってヒストグラムを描きましたがすでにグループ分けされている値でヒストグラムを描くこともできます。 曜日ごとの顧客数のヒストグラムを描いてみます。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='曜日')
fig.update_layout(yaxis=dict(title='顧客数'))
fig.show()
実行結果
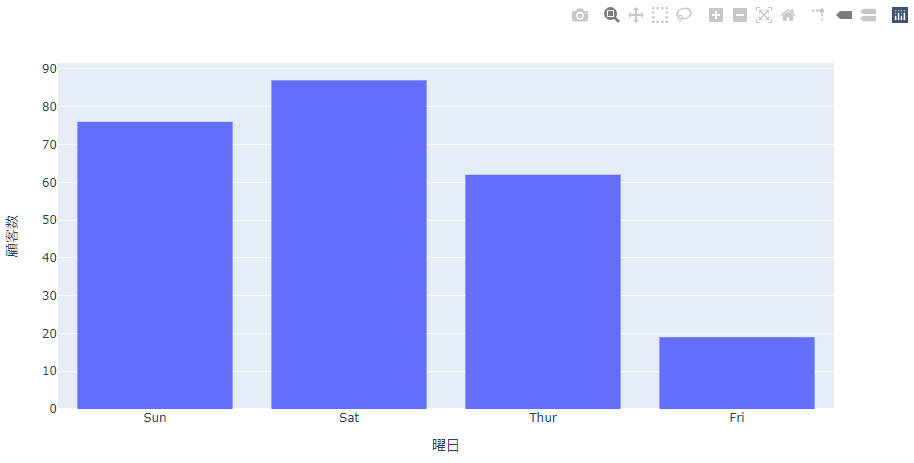
実行結果をみてもらうとわかる通り、曜日ごとにグループ化されて表示されています。連続値ではないため、グラフの間は詰められることなく最初から間があいています。
グループでヒストグラムを描く際には、表示順を指定したほうが良いことがほとんどとおもいます。 しかし上の結果を見ると曜日順になっていません。そのため曜日順になるように変更します。
import plotly.express as px
df = px.data.tips()
df.rename(columns={'total_bill':'支払合計額','tip':'チップ','sex':'性別','smoker':'喫煙者','day':'曜日','time':'時間帯','size':'サイズ'},inplace=True)
fig = px.histogram(df, x='曜日',category_orders=dict(曜日=["Thur", "Fri", "Sat", "Sun"]))
fig.update_layout(yaxis=dict(title='顧客数'))
fig.show()
実行結果
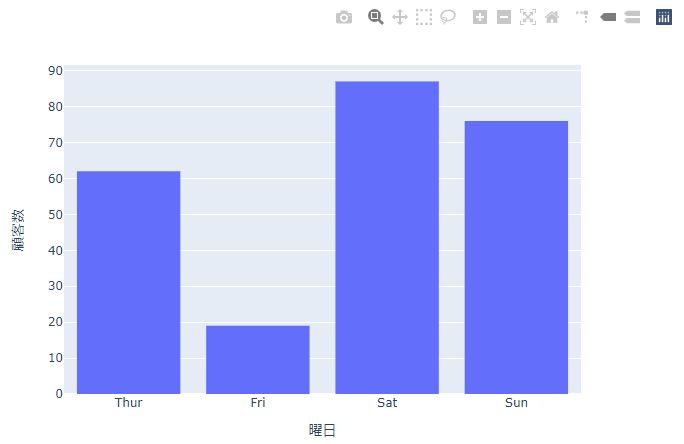
曜日順に表示されました。
まとめ
PlotlyExpressのヒストグラムで良く使いそうなオプションについて公式ページを元に解説してみました。 細かいオプションの説明については「 plotly.express.histgram 」をみてみてください。
ここで紹介しきれないオプションも多数のっています。
この記事へのコメント
コメントはまだありません。
コメントを送る