背景
今回の記事のきっかけについて説明させてください。
有名なブロガーでもあるYoutuberの一言 「キーワードのランキングチェック。それが正しいブロガーのあり方です」。
それが始まりでした。最初は「そうしてまでアクセス数が欲しいのか?」と思いましたが、動画を見ているうちになるほどと思いました。
最近の検索エンジンが高性能になっている事を知っている人は多いと思います。検索キーワードを入れると、広告をのぞく上位サイトにはほぼ目的とする検索結果が含まれています。それだけでなく、非常に見やすい文章構成となっていることが多く、読み手のことをよく考えている構成となっています。そのブロガーの主張によると記事で書きたいことをキーワードに起こして、そのキーワードを元に検索結果の上位を目指すことで自然と読者に寄り添った記事になるという話でした。さらに記事を書く前にターゲットのキーワードのランキング上位サイトを一通り分析しキーワードを中心に読者にどのような配慮をおこなって記事を構成しているか分析するとのことです(やはり結果を残している方は違います)。
全ての改善活動で重要な事は「効果が測定できる事」(可測)である。とだというのは知っています。ブログの善し悪しを判断するのに、検索エンジンのランキングを改善活動の指標にするのは非常に理に叶っていると思いました。私はSEでもあります。SEの正しいあり方はどう世の中の課題をシステムとして形にするかです。ブロガーでありSEでありプログラマーでもある私はどうあるべきか。そこから導き出される答えはごく自然なものでした。
- 「どうせなら自分用にカスタマイズしたランキングチェック用のプログラムを作ろう」
- 「ついでに記事にしよう」
- 「pythonがはやっているみたいだからpythonで書いてみよう」
- 「この記事を元に仕事がこないかな…」
最後1つは不純な動機かもしれませんが、面白そうなのでpythonでキーワードランキングチェッカーを作ってみることにしました。ちなみにここまで書いたことはすべて建前で本当のことろは単純にPythonでプログラミングをして息抜きをしたかっただけだったりします。ちなみにここで作成するのは自動化などのために実行するものではなく手で入力することでチェック結果を残す程度のものです。もしごりごりとバッチを組んでこのプログラムを何回も実行するとGoogleの検索サイトにロボット判定を受けてアクセスブロックを受ける可能性があります。ですので、そのようなことは止めてください。
検索ワードを手動で入力するのではなく、自動実行するのであればGoogleがCustom Search API、というものを用意していますのでそちらを使ってください(Googleの宣伝もしておきます)。
もう一つの目的としてYoutbueでPythonで実装コーディングしている動画を見て、楽しそうな、かっこいい仕事だと思っているSE志望の人に対して、実際のSEの開発や実装ははこんな感じなんだよと知ってもらいたいという思いがありました。
上記の様々な目的を持ってこのブログを書くこととなりました(ここで欲張るのが本来の間違いだと後で知ることになるのですが…。目的はシンプルに一つる絞るのが良いソリューションと知っているにもかかわらず…)。
要件定義
まずは何を作るのかはっきりさせておきます。
要件定義前半
SEとして大切なことは要件としてきちんと文章に落とし込むことです。本当は要件の前に要求があるのですが、今回は要求も、プログラムを作るのも私一人なので、最初から要件を作り上げても問題ないでしょう。
要求と要件の違いについてはどこかでやるかもしれません。今すぐ知りたい人は申し訳ありませんがGoogle先生に聞いてみてください。
機能要件として以下をあげました。
- キーワードを入力すると検索エンジンのランキング結果、上位サイトのURL、タイトル、調査日時を抽出しDBに格納する
- ランキングの中に自サイトがあった場合、わかるようにフラグを立てておく
まずは上記を目標とします。次の段階で記事内容までの分析をおこないたいのですが、まずは上記2つを機能要件としてあげることにしました。
非機能要件としては以下とします
- 初心者が学習、保守しやすいように1ファイルにまとめできるだけコンパクトに作る
- エラーが出たら標準エラー出力に出力する
機能要件と非機能要件については別途ブログを書くかもしれません。
実際の業務では機能要求にしろ非機能要求にしろどこまでおこなうかは、予算や納期、開発や運用の体制など周りの環境に影響されます。どこまで必要でどこを行わないか。関係者の合意をとるのが、プロジェクトマネージャやSEとして正しいありかたというのは覚えておいてください(特にフリーランスのSEだと重要です。自分の身を守るためにも)
要件定義後半(実現方法の調査)
要件定義の後半では実現方法について考えます。会社によっては要件定義工程を業務要件定義とIT要件定義と分けることがありますが、この工程でIT化するとしたらどのような技術で実現するか、IT化する部分、しない部分を考えます。
今回はキーワードの検索順位を得るのが目的ですが、検索結果のランキングを得るには検索エンジンにアクセスしてキーワードを入力して検索を行い、出力結果を読み込んで処理する必要があります。プログラムは初心者が読みやすいように1つのファイルにまとめられる長さを目指します。
言語によって用いるライブラリが異なりますが、比較するため表にまとめてみます。
ソリューションの比較
| # |
言語 |
環境構築 |
スクレイピング |
dbへのアクセス |
ファイル数 |
| 1 |
Java |
× |
jsoup |
JDBC/JPA |
× |
| 2 |
Python |
〇 |
Beautiful Soup |
PEP249 / SQLAlchemy |
〇 |
| 3 |
Go |
△ |
goquery |
sql / gorm |
△ |
| 4 |
Node.js |
△ |
puppeteer/cheerio-httpcli |
node-sqlite |
× |
様々のブログを見て実装しやすさを調査したところJavaのjsoupは記述が簡潔で実装しやすそうです。しかしライブラリやdbアクセスするための環境を用意することを考えると環境構築が大変というのが私の評価でした。mavenやgradleで利用ライブラリを記述してコマンドを打ってIDEに利用ライブラリを教えて、ビルドして…という環境を構築するのはさすがに面倒です。これがプロジェクトであれば、環境構築分の投資を十分に取り返せると思うのですが今回は割にあいません。
一方で、Pythonは記載しやそうとの印象をうけました。コンパイル言語ではなくスクリプト言語であること、昔みたいに様々な環境構築方法があって意味不明なこともなく今はpipでほとんど済むことも高評価です。心配なのは処理速度でしょうか。DB処理も簡単に扱えそうです。
GoはJava同様コンパイル言語ですがJavaに比べ環境構築はやりやすそうに感じました。並列処理が得意ということですが、並列にスクレイピングしているソースを見たところ、ボリューム的に難しそうです。本格的に並列処理を考えるのであれば良いですが、今回は手でぽちぽち入力して記録を残す程度のものなので今回の要件にはあいません。Custom Search APIを読んでごりごり検索順位を取得するであれば候補になるでしょう。DBへのアクセスのやりやすさはPythonとJavaの間くらいでしょうか。
Node.jsもJavaほどではありませんがpackage.jsonとか環境まわりは面倒くさそうです。DBアクセス周りも面倒な気がしました。Javascriptは言語仕様的に品質を保つのが難しくイベント駆動で入れ子の階層が深くなりがちなのでフロント周りを触るのでなければ避けたいところです。
上記色々と考えた結果、言語はPythonでスクレイピングはBeautiful Soupを用いる。ORMはSQLAlchemy、DBはシンプルにSQLiteを用いて取得してきたデータを格納することとしました。
プロジェクトでお金をかけて体制を組めるのであればJava、非常に高い性能を求められるのであればGo、フロントと同じスキルセットで開発したいのであればNode.jsを選ぶのが良いような気がします。
本業でおこなう場合には、ログ出力やエラー監視など様々なことを考慮することがありますが今回は考慮から外すことにします。
基本設計
基本設計は顧客にシステムの説明をおこない合意を得るための資料として作成します。そのため機能や格納するデータやデータの相関関係をドキュメントとして残します。
機能設計
実現方法が決まったところで設計をおこなってゆきます。今回の機能は主に2つ。
- キーワードによるサイト毎の順位調査
- 記事のキーワード順位調査
ただし両方同じような機能なのでまとめてしまいます。以下のようにコマンドラインで実行することにします。
py RankingCheck.py [--drop] [-u URL] [-o DBファイル名] [-m 調査最大順位] キーワード1 [キーワード2] [キーワード3] …
- キーワードでGoogle検索をおこなった際の順位ランキングをデータベースに出力する
- dropオプションを付与すると検索前にいったんデータベース上のテーブルをすべて削除する
- uオプションで自分の運営するサイトのURLを指定できる。DB上ではドキュメントの自ページフラグがTrueで登録される
- oオプションで出力先のSQLiteのファイル名を指定できる。指定しない場合にはデフォルト値"ranking.sqlite3"で出力される
- mオプションで何位まで調査するかを指定する
- []で囲まれているのは省略可能な引数
データ設計
今回はデータの格納場所として上述したとおり、SQLiteをもちいます。SQLiteはRDBと呼ばれる種類のデータベースです。他にRDBにはOracleやPostgreSQL、MySQLなどがあります。
RDBは表(テーブルと呼ばれる)と表の関係(リレーションシップ)を用いてデータの格納、検索をおこないます。そのため設計ではテーブルとテーブルの関係性(あるテーブルのデータ1件に対して、他のテーブルのデータが何件存在するか)を設計してゆきます。他にも色々と設計要素があるのですが今回は規模からなくても良いと思い省略します。
テーブル設計
テーブルを網羅なく洗い出します。今回は以下のテーブルで作成することします。
テーブル一覧
| # |
テーブル名 |
識別子 |
説明 |
| 1 |
検索 |
T_SEARCH |
検索1回あたり1行が対応。検索日時を保存 |
| 2 |
キーワード |
T_SERACH |
どのようなキーワードで検索をおこなったかを格納 |
| 3 |
ランキング |
T_RANKING |
検索ランキング順位がページごとに格納される |
| 4 |
ドキュメント |
T_DOC |
サイトのURLを格納 |
ER図
テーブル間のリレーションを明らかにするためER図を書きます。
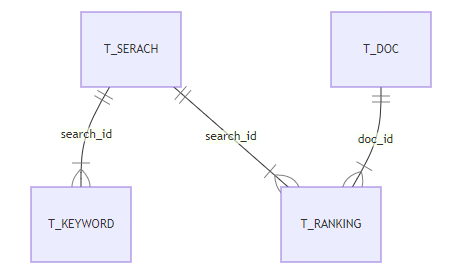
上記を文章にすると以下のようになります。
- 検索1件に対しキーワードは複数ある(「ブログ」「面白い」など複数のキーワード)
- 検索1件に対し順位は複数ある(1位、2位、3位…)
- ホームページのドキュメント(URL)1件に対し順位は複数ある(〇〇のキーワードで〇〇日に2位、△△のキーワードで〇〇日に4位…)など
もっといろいろとありますが、だいたいのイメージをとらえることができれば十分です。 この関係性が理解できていないと、詳細設計や実相寺にデータベースにデータを格納してゆく順番がおかしなことになったりします。 このER図だと実装時には以下の順番でIDの取得とデータの格納をおこなうことになります。
- T_SERACH登録(T_SEARCHのIDを取得)
- T_KEYWORD登録(T_SEARCHのIDを格納)
- T_DOC登録(T_DOCのIDを取得)
- T_RANKING登録(T_SEARCHのIDとT_DOCのIDを格納)
ちなみにこのER図はMermaidと呼ぶ記法で記述しています。システム設計で用いる図のいくつかを記号で記載することで上記のような図に起こしてくれます。たとえば今回は以下のような記載をおこなっています。
```mermaid
erDiagram
T_SERACH ||--|{ T_KEYWORD : search_id
T_SERACH ||--|{ T_RANKING : search_id
T_DOC ||--|{ T_RANKING : doc_id
```
業務ではExcelやWord、場合によってはPowerpointでの設計書の納品が多いですが、最近ではMarkdownと呼ばれる形式での納品もあります。
詳細設計
詳細設計は基本設計をプログラムをおこなうのに必要なレベルまで詳細化するためにおこないます。プログラマに仕様の詳細を説明するための資料になります。
DB物理設計
今回は作るものがシンプルですので単純にテーブル設計のみにとどめます。本当はもっと様々な設計要素があります。
T_SEARCH(検索)
| 項目名 |
型 |
制約 |
説明 |
| id |
int |
PK |
サーチID |
| search_datetime |
int |
|
検索日時 |
T_KEYWORD(キーワード)
| 項目名 |
型 |
制約 |
説明 |
| id |
int |
PK |
キーワードID |
| search_id |
int |
FK |
外部キー |
| keyword |
text |
|
キーワード文字列 |
T_RANKING(ランキング)
| 項目名 |
型 |
制約 |
説明 |
| id |
int |
PK |
ランキングID |
| search_id |
int |
FK |
外部キー |
| doc_id |
int |
FK |
外部キー |
| ranking |
int |
|
検索順位 |
T_DOC(ドキュメント)
| 項目名 |
型 |
制約 |
説明 |
| id |
int |
PK |
ドキュメントID |
| link_url |
text |
|
リンクURL |
| mypage_flg |
int |
|
自ページフラグ |
関数設計
関数の呼び出し仕様などを納品する際には、ソースコードにdocstringを記載し、その出力を納品することも多いです。最初の段階では引数は決めず以下のようにざっくりとした役割分けのみおこない、設計や開発をすすめてゆく中で引数や戻り値を確定させ、ソースコードにドキュメントテーション文字列コードを入力します。
関数一覧
| # |
関数名 |
物理名 |
役割 |
| 1 |
メイン処理 |
main |
コマンドラインからの引数やオプションを受取り引数処理を実行後、必要な処理を呼び出す |
| 2 |
検索処理 |
search |
検索対象となるキーワードと検索をDBに登録し検索エンジンに検索キーワードをなげる準備を整え検索開始処理を呼び出す |
| 3 |
検索開始 |
__search_start |
検索結果の最初の1ページの処理をおこないDB登録更新処理を呼び出す |
| 4 |
次頁検索 |
__search_next |
検索結果の2ページ以降の処理とおこないDB登録更新処理を呼び出す。次のページがある場合には自分自身(__search_next)を呼び出す(再帰呼び出し) |
| 5 |
DB登録更新処理 |
__db_upsert |
スクレイピングで要素を抽出し結果をDBに登録する処理をおこなう |
シーケンス図
設計中に、これは図にしないとわかりにくい、他の人に伝え難いという際にはシーケンス図を記載します。後づけで記載することも多いです。今回は後付けで記載しました。
図を見て改めて「検索開始」と「次項検索」は一つにまとめてループ処理にしたほうが良かも…とおもいました。どこかで書き直すかもしれません。
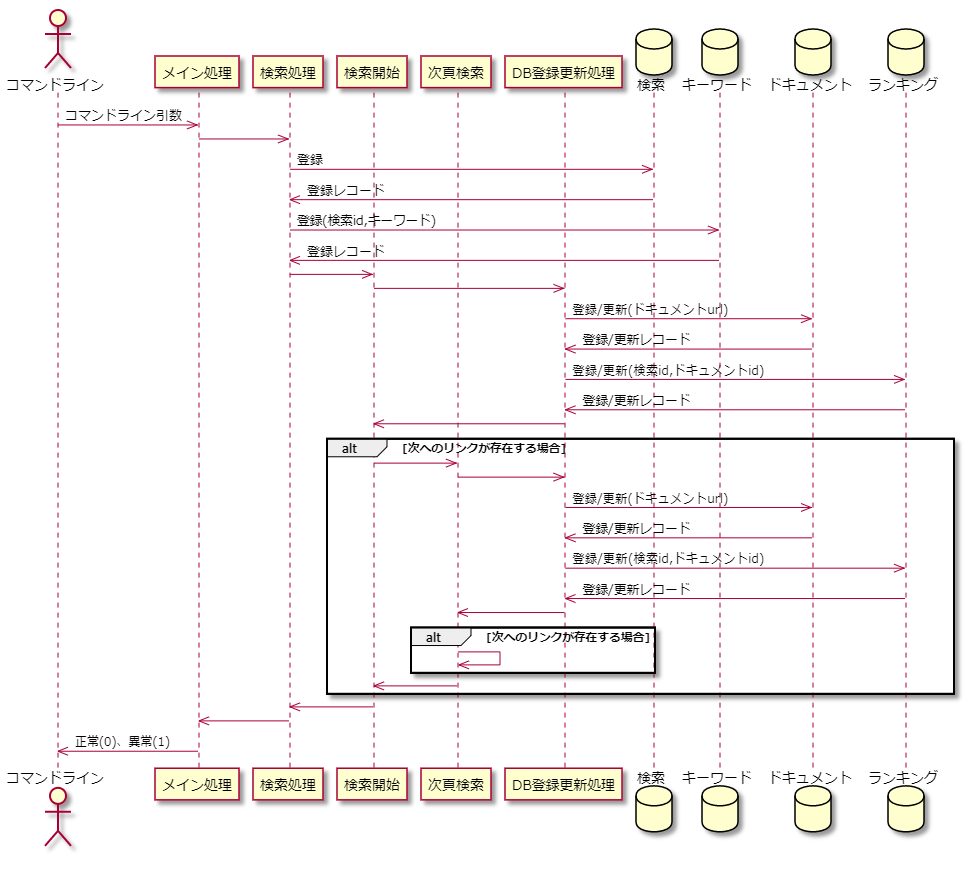
このように図を書いたら全体の流れで悪い部分がはっきりするのもシーケンス図の良い点です。この図はPlantUMLという記法で書いています。前述したMermaidと同じようにテキストベースで記載してゆくものです。長いのでPlantUMLでの記載は記載しませんが、今回の成果物については後でGitHubにあげるので気になる人はそこでみてください。
実装
実装にはいってゆきます。どこから記載するか方法は色々ありますが、私はまず例外をキャッチする部分を記述し、その後はハードルが高そうな部分からすすめます。ハードルが高い部分を後に回すと設計に変更が生じる可能性がおおきく、そうなると他の部分に与える影響が大きくなるからです。今回はBeautiful soupで取得する部分か、DBに書き込む部分について最初に実装していったほうが良いでしょう。
実装後の結果にについてGitHubにあげているのでそちらをみてみてください。
事前準備
Pythonの3.9以降を利用して以下でパッケージをインストールしてください。
pip install sqlalchemy requests beautifulsoup4 lxml
例外処理の実装
まず最初に例外処理を実装してゆきます。例外処理については、実装中に記載してゆかないと後で発生する例外を調べようとしても再現が難しい場合や適切な判断(プログラムを異常終了すべきか継続すべきか)が判断できない場合があります。そのため実装中に例外が発生した場合には、必ず同時に例外発生時の処理を実装するようにしましょう。
今回は漏らした例外はかならずコマンドライン側でキャッチできるように以下のような記述を記載しています。
if __name__ == '__main__':
try:
main(sys.argv)
except Exception as e:
(exc_type, exc_value, exc_traceback) = sys.exc_info()
t = traceback.format_exception(exc_type, exc_value, exc_traceback)
pprint.pprint(t, width=120,stream=sys.stderr)
sys.exit(1)
sys.exit(0)
ここで例外が補足された場合には、どこでどのような例外が発生したか出力されるため、原因箇所までさかのぼって例外の実装を追記してゆきます。
DB処理の実装
シーケンス図の検索処理の部分でDBへの接続をおこなっています。クォート3つで囲まれてる部分2行目の"""から"""の行まではソースコードの説明を記載する部分でdocstringと呼ばれています。IDEで関数を記述した際にここに記載した内容がPOPUPで表示されます。この部分は記述しなくてもプログラムの動作には影響ありません。実際の処理は「connect_string = "sqlite:///{}".format(dbfile)」から実行されます。
def search(keywords: list[str], dbfile: str, url: str, max_ranking: int, drop_flg: bool):
"""検索処理
検索処理に必要な前処理をおこない検索開始を呼び出す
Parameters
----------
keywords : list[str]
検索キーワードの配列
dbfile : str
データベースファイル名
max_ranking : int
何位までランキングを検索するか
drop_flg : bool
TrueのときテーブルをいったんDROPして作成しなおす
"""
connect_string = "sqlite:///{}".format(dbfile)
engine = sqlalchemy.create_engine(connect_string, echo=False) # SQLとデータを出力したい場合はecho=Trueにする
try:
session = scoped_session(
sessionmaker(
autocommit = False,
autoflush = True,
bind = engine))
Base.query = session.query_property()
if drop_flg:
Base.metadata.drop_all(engine)
Base.metadata.create_all(engine)
if len(keywords) > 0 and max_ranking > 0:
t_search = TSearch()
dttime = datetime.now()
t_search.search_datetime = dttime
t_search = TSearch().upsert(t_search,session)
for keyword in keywords:
t_keyword = TKeyword()
t_keyword.keyword = keyword
t_keyword.search_id = t_search.id
t_keyword = TKeyword().upsert(t_keyword,session)
__search_start(session, t_search, keywords,max_ranking, dttime ,url)
except Exception:
raise
else:
session.close()
finally:
engine.dispose()
いきなり途中で「Base.query = session.query_property()」という記載がでできていますがこのBaseはSQLAlchemyでテーブルクラスの既定クラスとして定義しているもので、このプログラムの一番先頭で「Base = declarative_base()」という定義があります。
「if len(keywords) > 0 and max_ranking > 0:」のif文の中でT_SEARCH(検索)テーブルへのデータ登録をおこなうメソッドを呼び出しています(「t_search = TSearch().upsert(t_search,session)」の部分)。さらにその内側のfor文「for keyword in keywords:」の中ではT_KEYWORD(キーワード)テーブルへのデータ登録をおこなうメソッドを呼び出しています(「t_keyword = TKeyword().upsert(t_keyword,session)」の部分)。T_SEARCHデータ登録時に登録したレコードを戻すことでT_SEARCHの登録時に採番されたidを取得し、T_KEYWORDのレコードの登録時に用いています(for文の中の「t_keyword.search_id = t_search.id」の部分)。
各DBへの登録更新処理に接続時に作成したセッションと登録更新する情報を引き渡しています。
実際にテーブルを登録更新する部分「 TSearch().upsert(t_search,session)」は以下のようになります。
Base = declarative_base()
class TSearch(Base):
"""検索
データベースの検索テーブルに対応するオブジェクト。
検索を格納している。
Attributes
----------
id : int
検索ID 自動採番
search_datetime : datetime
検索日時
"""
__tablename__ = 't_search'
id = Column(Integer, primary_key=True, autoincrement=True)
search_datetime = Column(DateTime, nullable=False)
@staticmethod
def upsert(t_search,session: scoped_session ):
"""登録更新処理
search_datetimeで検索しレコードが存在しない場合にINSERTをおこなう。
データが変更されていた場合はなにもおこなわない。
(id以外に項目がsearch_datetimeのみのため処理の必要がない)。
Parameters
----------
t_search: TSearch
登録更新対象のデータ
session: scoped_session
データベースへの接続セッション
Returns
-------
ret_t_search: TSearch
処理完了後のレコードが戻る
"""
ret_t_search = session.query(TSearch).filter(TSearch.search_datetime==t_search.search_datetime).first()
if ret_t_search is not None:
return ret_t_search
else:
session.add(t_search)
session.commit()
return t_search # commit後なのでidが採番されている
記述の大部分がdocstringになっていまっていますが、実際の実装で重要なのは最後の7行の部分です。日時で検索して検索テーブルにデータが登録されていれば何もしません。登録されていなければ新たにデータを登録します(else:の中の処理)。登録後のIDの値が必要ですので、commit後のt_searchを返却しています。
今回は説明のためdocstringを一通り記載していますが、このような単純な処理のdocstringをどうするかはプロジェクト次第とおもいます。予算は限りがあります。SQLAlchemyはドキュメントよりソースコードの視認性のほうが高いと考えているので、テーブル更新系のメソッドの処理内容は命名規約で決めておきて、規約で決められた範囲のdocstringの記載は簡略化し1行のみの説明とするのも良いと思います。Pythonはこのdocstringの書き方の流派も主なもので3つほどあるそうです。今回はNumPyスタイルと呼ばれるスタイルで記載しました。Pythonでは行列演算をおこなうためのNumPyと呼ばれる有名なライブラリがあるのでそこから来ているのでしょう。
スクレイピング処理
スクレイピングをおこなう部分の処理をみてゆきます。
def __search_start(session: scoped_session,t_search: TSearch, keywords: list[str], max_ranking: int,search_time: datetime, my_url: str) -> int:
"""検索開始
検索結果の最初の1ページの処理をおこないDB登録処理を呼び出す
Parameters
----------
session : scoped_session
データベース接続のセッション
t_search : TSearch
検索テーブル
keywords : list[str]
検索キーワード
max_ranking : int
何位までランキングを検索するか
search_time : datetime
検索を開始した日時
my_url : str
自サイトのURL
Returns
-------
ranking : int
処理完了したランキング順位
"""
google_url = "https://www.google.co.jp/search"
search_word=""
for keyword in keywords:
search_word = "{} \"{}\"".format(search_word,keyword)
r = requests.get(google_url,params={'q': search_word})
soup = BeautifulSoup(r.text, 'lxml') #要素を抽出
ranking=0
ret_ranking = __db_upsert(session, soup, t_search, ranking, max_ranking, search_time, my_url)
if ret_ranking >= max_ranking:
return ret_ranking
a = soup.select_one("a[aria-label='次のページ']")
if a is None:
return ret_ranking
link_text=a.get("href")
return __search_next(session, t_search, link_text, ret_ranking, max_ranking, search_time, my_url)
検索サイトのURLをセットし、検索サイトに問い合わせるキーワードを組み立てます。
「r = requests.get(google_url,params={'q': search_word})」の部分でリクエストをなげ検索結果を受取ります。受け取った結果を次の行「soup = BeautifulSoup(r.text, 'lxml') #要素を抽出」でBeautiful soupに渡してスクレイピングの準備をおこないます。
実際に中の順位を検索してDBに登録しているのは「ret_ranking = __db_upsert(session, soup, t_search, ranking, max_ranking, search_time, my_url)」の部分でこの「__dp_upsert(DB登録更新処理)」の中で要素抽出とDB書き込みを実施しています。
全体の流れは既出のシーケンス図をみてもらえばわかるとおもいます。 ページのスクレイピングが終わり「次のページ」がある場合には次頁検索の処理を呼び出します。次項検索の処理内容の大部分は変わらないため省略しますが、気になる人はGitHub上でソースをみてください。
ではランキングの要素抽出とDB登録をおこなっている「DB登録更新処理」の中身をみてゆきます。
def __db_upsert(session: scoped_session,soup: BeautifulSoup, t_search: TSearch, ranking: int, max_ranking: int,search_time: datetime, my_url: str) -> int:
"""DB登録更新処理
得られた検索結果をスクレイピングし検索結果をDBに登録する処理をおこなう
Parameters
----------
session : scoped_session
データベース接続のセッション
soup : BeautifulSoup
検索結果読み込み済みのBeautifulSoupのオブジェクト
t_search : TSearch
検索テーブル
ranking : int
何位のランキングまで処理完了しているか
max_ranking : int
何位までランキングを検索するか
search_time : datetime
検索を開始した日時
my_url : str
自サイトのURL
Returns
-------
ranking : int
処理完了したランキング順位
"""
search_time_string = search_time.strftime('%Y%m%d_%H%M%S')
if not os.path.exists(search_time_string):
os.makedirs(search_time_string)
with open("{}{}bs_{}.html".format(search_time_string,os.sep,str(ranking)), 'w', encoding='UTF-8') as f:
f.write(soup.prettify())
divs = soup.select("[class='ZINbbc xpd O9g5cc uUPGi']")
for div_b in divs:
if ( div_b.div.a is not None ) and (div_b.div.h3 is not None):
ranking = ranking + 1
link_text=div_b.div.a.get("href")
link_text=link_text.replace('/url?q=','').split('&')[0]
doc_title=div_b.div.h3.div.get_text().strip()
t_doc = TDoc()
t_doc.link_url = link_text
t_doc.title = doc_title
if len(my_url) > 0 and my_url in link_text:
t_doc.mypage_flg = True
else:
t_doc.mypage_flg = False
t_doc = TDoc().upsert(t_doc, session)
t_ranking = TRanking()
t_ranking.search_id = t_search.id
t_ranking.ranking = ranking
t_ranking.doc_id = t_doc.id
has_ranking = TRanking().hasRanking(t_ranking, session)
if has_ranking == True:
# 二重にランキング計上されているためインサートせずrankingから1を引いておく
ranking = ranking - 1
else:
#t_ranking = TRanking().upsert(t_ranking, session)
t_ranking = TRanking().insert(t_ranking, session)
if ranking == max_ranking:
return max_ranking
return ranking
最初のほうの処理、「search_time_string = search_time.strftime('%Y%m%d_%H%M%S')」から「 f.write(soup.prettify())」は、検索結果として得られたhtmlをファイルに書き込む処理をおこなっています。これはスクレイピングをおこなってゆく際の要素抽出で要素を抽出する際にどのうよなhtmlが取得できたか知っておく必要があるためです。日時にわけてフォルダを切って取得できたhtmlを格納しています(デバックや検索サイトの仕様変更の際に、分析するために必要な情報にもなります)。指定する要素はこのhtmlをみながら考えてゆきます。
「divs = soup.select("[class='ZINbbc xpd O9g5cc uUPGi']")」の部分で実際に順位を抽出しています。その中からさらに雑音をのぞいた順位とおもわれる部分をif文でえり分けて抽出しています。
抽出したサイトのURLリンクをlink_textにタイトルをdoc_titleに格納しt_docのテーブルに登録更新後、t_rankingのテーブルに順位を登録しています。
長くなりましたが以上がメイン部分の実装となります。
テスト
通常、単体テストはホワイトボックステスト。結合テスト以降はブラックボックステストを行います。自動テストを実施する場合はテストコードを書いて期待通りの動作をおこなっているか、テストに漏れがないか、テストのカバー率、カバー率が落ちている場合には原因は何かを確認しながら品質を確保します。今回は自動テストはおこないません。自動テストをおこなわない理由を説明するために、どのような環境で自動テストがおこなわれているか述べさせてください。
私が本業で努めている会社は基幹システムでの自動テストを導入しており、単体テストを実行しできるだけすぐにバグを検出できる環境がととのっています。
このような仕組みが必要な背景として基幹システムは多数のチームが同時に手を入れているとう現実があります。プロジェクトマネージャも別々の人が担当しているので、こういった仕組みを用意しないとバグの早期検知が難しいというのがあります。またいつだれがどのような経緯でバグを混入させたかリリース前に追いたいという背景もあります。リリース周期も2週間に1回と早いです。ミドルや言語のバージョン変更、EOLS対応などで移行が必要な場合にも新しいバージョンに入れ換えた後、テストを実行してエラー部分をつぶしてリリースします。
逆に同時に複数のチームが手を入れるプロジェクトがないプロダクトで自社開発かつミドルやOSの入れ換えも頻繁になく、サポートする環境(デバイス)が少なく(あるいは固定されており)リリースタイミングが4半期に1回程度の場合には、自動テストは過剰なソリューションになるとおもいます。
大切なのは、はやっているからやるのではなく、必要なソリューションだからその技術を使うということを忘れないでください。そして本当に自動テストが必要かどうか考えてください。
今回は、利用するのが私のみのため、テストについては正常系と異常系一通り動作を確認できれば良いとして自動テストはおこなわないことにしました(ブログネタとして別件で自動テストについてはやるかもしれません)。
「テスト仕様書兼テスト結果報告書」を作成しテストを実施します。データベースの中身をみるのは面倒なのでテストに先立ちDBの中身をみるためのツールを何か用意しておくことをおすすめします。接続するDBがOralceで「PL/SQL」を使う開発であればObject Browserなどの優れた有償ツールを使いますが、今回は単純にデータを見るだけということ、DBがSQLiteということもあり、「A5:SQL Mk-2」を用いました。「テスト仕様書兼テスト結果報告書」のテスト結果(成果物)と「A5:SQL Mk-2」へのリンクを張っておきます。
実際に「テスト仕様書兼テスト結果報告書」のNG部分をみてみればわかるとおもいますが、想定しにくい部分でNGの結果がでているのがわかります。このように動いているように見えても実際にテストしてみると、思わぬところで障害で出たりするのでテストは重要です。
運用・保守
今回は1日1回、手動でコマンドを動かし、結果を確認することとします。
自動化するとコマンド実行の手間を省くことができますが、その一方で、エラーが生じた際の監視のしくみなどを考える必要があります。またバッチ化してごりごり動かすと検索エンジンに迷惑がかかります。
あくまで手動で動かすのを想定します。
まとめ
システムエンジニア志望やプログラマ志望の人にSEやプログラマが頭の中で何を考えながら、システムを作っているのかおぼろげながらも理解してもらえればとおもいます。
反省
おもったことを色々と記載してゆくと文字数が増え、気がつくとこの記述量になっていました。全作業のボリュームとしてだいたい4人日分くらいでしょうか。実装は1日もかかっていませんが、文章を書いたりテスト仕様書兼結果報告書のフォーマットを考えたり、テストをして結果を入力したり、文章をまとめたり…。 よくエンジニアYoutuberの方がコードを書いている時間は2割くらいと言ってますが、そんなものです。
さすがにこんな量の記事を書いても、読む人はいないとおもいますので、今後は記事を小分けにしてゆくことにします。


この記事へのコメント
コメントはまだありません。
コメントを送る